Language and Embedding Models Abstraction
The Elemental library provides a unified interface for interacting with various language and embedding models. This abstraction allows developers to easily switch between different models and providers without changing the underlying code. It also defines a common structure for implementing new models, making it easier to extend the library with additional providers in the future.
Elemental supports multiple model providers, including OpenAI, Ollama, Anthropic, and Llama Cpp. Each provider has its own implementation of the LLM class, which adheres to the same interface. This allows users to easily switch between different models by simply changing the provider name and requested model in the configuration.
Language Models
Language Models module abstracts the implementation of different LLM providers. The module is organized into several classes, with LLM being the base class for all LLM implementations. The LLM class defines the common interface and functionality for all LLMs, while the specific implementations (e.g., OpenAILLM, OllamaLLM, etc.) provide the actual implementation details that are specific for each provider.
Common data model for Message and ModelParameters is used in the LLM module and is defined in data_models.py.
LLM module also includes LLMFactory class that provides a factory method for creating instances of LLMs given a framework and model as string parameter.
Figure below displays the logical organization of the module.
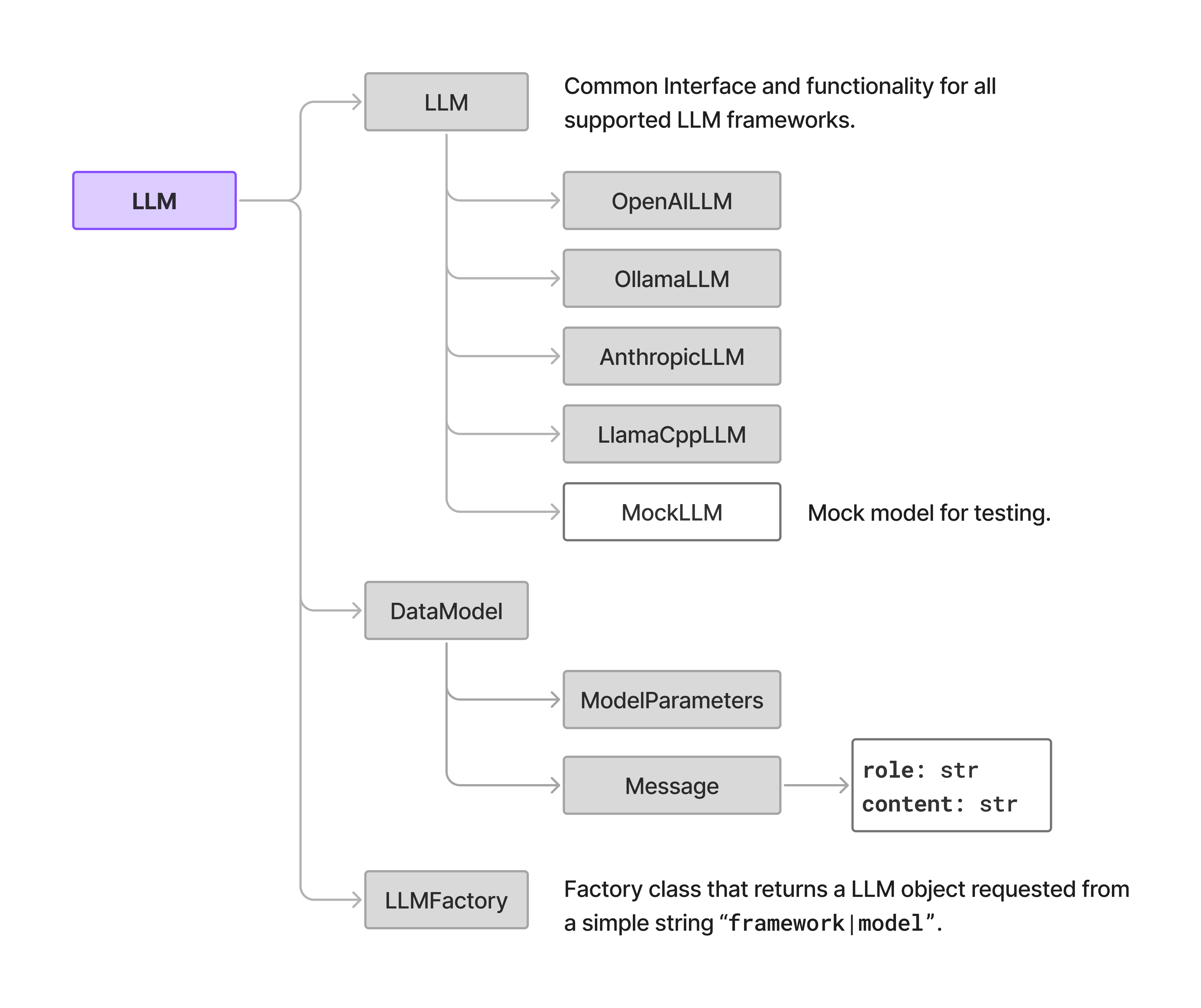
LLM class is the base class for all LLM implementations, while the specific implementations (e.g., OpenAILLM, OllamaLLM, etc.) inherit from it all common functionality.
The LLMFactory class provides a factory method for creating instances of LLMs. Message (following OpenAI standard) and ModelParameters are common data models used in the LLM module.LLM class
The LLM class is an abstract base class defining the interface and common functionality for Language Models (LLMs) within the Elemental framework. It supports both streaming and non-streaming modes of interaction with language models, including retry logic for robustness against network errors. The class manages model parameters, connection to a WebSocket server for streaming, and message processing.
Model initialization
def __init__(self,
model_name: str,
message_stream: bool = False,
stream_url: str = None,
parameters: ModelParameters = ModelParameters(),
url: str = None,
max_retries: int = 3,
) -> None
Parameters:
- model_name (str): Name of the model to be used.
- message_stream (bool): Flag indicating whether to use streaming mode.
- stream_url (str): URL for the WebSocket server for streaming responses.
- parameters (ModelParameters): Model parameters for the LLM.
- url (str): URL for the model API endpoint.
- max_retries (int): Maximum number of retries for network errors.
Specific Framework initialization may include additional optional parameter like API Key and URL for the model API endpoint.
The stream_url is only used when message_stream is set to True. The LLM class takes a role of the client to the WebSocket server and a connection is made separately for every message that needs to be generated. In our implementation we use socket.io library.
ModelParameters is defined in data_models.py as:
class ModelParameters(BaseModel):
"""
ModelParameters class that represents
the parameters for a language model.
"""
temperature: float = 0.0
stop: List[str] = None
max_tokens: int = 1000
frequency_penalty: float = 0.0
presence_penalty: float = 0.0
top_p: float = 1.0
- temperature (float): Sampling temperature for the model.
- stop (List[str]): List of stop sequences for the model.
- max_tokens (int): Maximum number of tokens to generate.
- frequency_penalty (float): Frequency penalty for the model.
- presence_penalty (float): Presence penalty for the model.
- top_p (float): Top-p sampling parameter for the model.
LLM messages are processed with run function defined with the signature:
def run(self, messages: List[Message], stop_word: str | None = None) -> str
Runs the LLM on the provided messages and returns the generated response. The messages parameter is a list of Message objects, which represent the input to the model. The stop_word parameter is an optional string that specifies a stop sequence for the model.
This function returns the content of the generated response as a string. Message object is defined with OpenAI standard with role and content members.
Framework specific classes
The specific initialization of the given framework may require additional parameters. For example, the OpenAILLM class requires an API key and URL for the OpenAI API endpoint. The OllamaLLM class requires a URL for the Ollama server.
Each framework-specific class inherits from the LLM class and implements the abstract methods defined in the base class. The specific implementations handle the details of interacting with the respective model provider's API, including authentication, request formatting, and response parsing.
Abstract Methods are:
Run the model in non-streaming mode and return the response.
def _run_non_streaming(self, messages: List[Dict], stop_list: List[str]) -> strmessagesparameter is a list of dictionaries representing the input messages, and thestop_listparameter is a list of stop sequences for the model.Asynchronously process the streaming response from the model.
async def _process_stream(self, messages: List[Dict], stop_list: List[str]) -> AnyLLMclass, which manages the connection to the WebSocket server and the streaming of messages. The exact function to extract the content from the stream is defined below.Extract content string from a chunk of streaming data.
def _extract_content_from_chunk(self, chunk: Any) -> Optional[str]return chunk.choices[0].delta.content
Elemental includes the support for the following frameworks:
| Class | Description |
|---|---|
OpenAILLM | OpenAI LLM implementation. This class is used to interact with OpenAI's language models. Details on the OpenAI API can be found in the OpenAI API documentation. The class handles authentication, request formatting, and response parsing for OpenAI's models. List of the models is also available at https://platform.openai.com/docs/models. |
AnthropicLLM | Implementation of the Anthropic LLM. This class is used to interact with Anthropic's language models. Details on the Anthropic API can be found in the Anthropic API documentation. Details about the models can be found at https://docs.anthropic.com/en/docs/about-claude/models/all-models. |
OllamaLLM | Ollama is an open-source platform for running large language models locally. Details on the Ollama can be found in the Ollama API documentation. Library of available models may be accessed here. |
LlamaCppLLM | Llama.cpp is a local inference engine optimized for running smaller model on both CPU and GPUs. It supports wide range of models in GGUF format. GGUF models may be downloaded and installed from the Hugging Face page. |
MockLLM | Class used only in unit testing to simulate the behavior of a language model. It is not intended for production use and does not provide any actual language generation capabilities. The class is used to test the functionality of the LLM module without relying on external dependencies or network calls. |
Additional frameworks may be used with their OpenAI interface which is commonly used and supported by many LLM providers in addition to their native API interfaces. For example Google, xAI, Docker Model Runner provide the OpenAI interface compatibility mode.
LLM Factory
LLM Factory is a class that provides a factory method for creating instances of language models. It abstracts the process of instantiating different LLM classes based on the provided engine name and model parameters. The factory method is responsible for selecting the appropriate LLM class based on the engine name and returning an instance of that class.
LLM Factory create function is defined in llm_factory.py as:
def create(
self,
engine_name: str = None,
model_parameters: ModelParameters = None
) -> LLM
Creates an instance of a language model based on the provided engine name and model parameters. The engine name is a string that specifies the type of LLM framework and language model to be created in the format provider_name|model_name, where provider_name is the name of the LLM provider (e.g., "openai", "ollama") and model_name is the name of the specific model to be used. The provider name can be one of the supported LLM frameworks in Elemental such as "openai", "ollama", "llama_cpp", "anthropic". The model parameters are optional and can be used to customize the behavior of the language model.
Parameters:
- engine_name (str): Name of the language model engine and model to be used in
provider_name|model_nameformat. - model_parameters (ModelParameters): Parameters for the language model.
Embedding Models
Implementation of the embedding models is similar to the LLMs. The Embedding class is an abstract base class defining the interface and common functionality for Embedding Models (EMs) within the Elemental framework.
This module also defines data structure for the Embedding object and EmbeddingsFactory class that provides a factory method for creating instances of embedding models given a framework and model as string parameter.
Figure below displays general organization of the module.
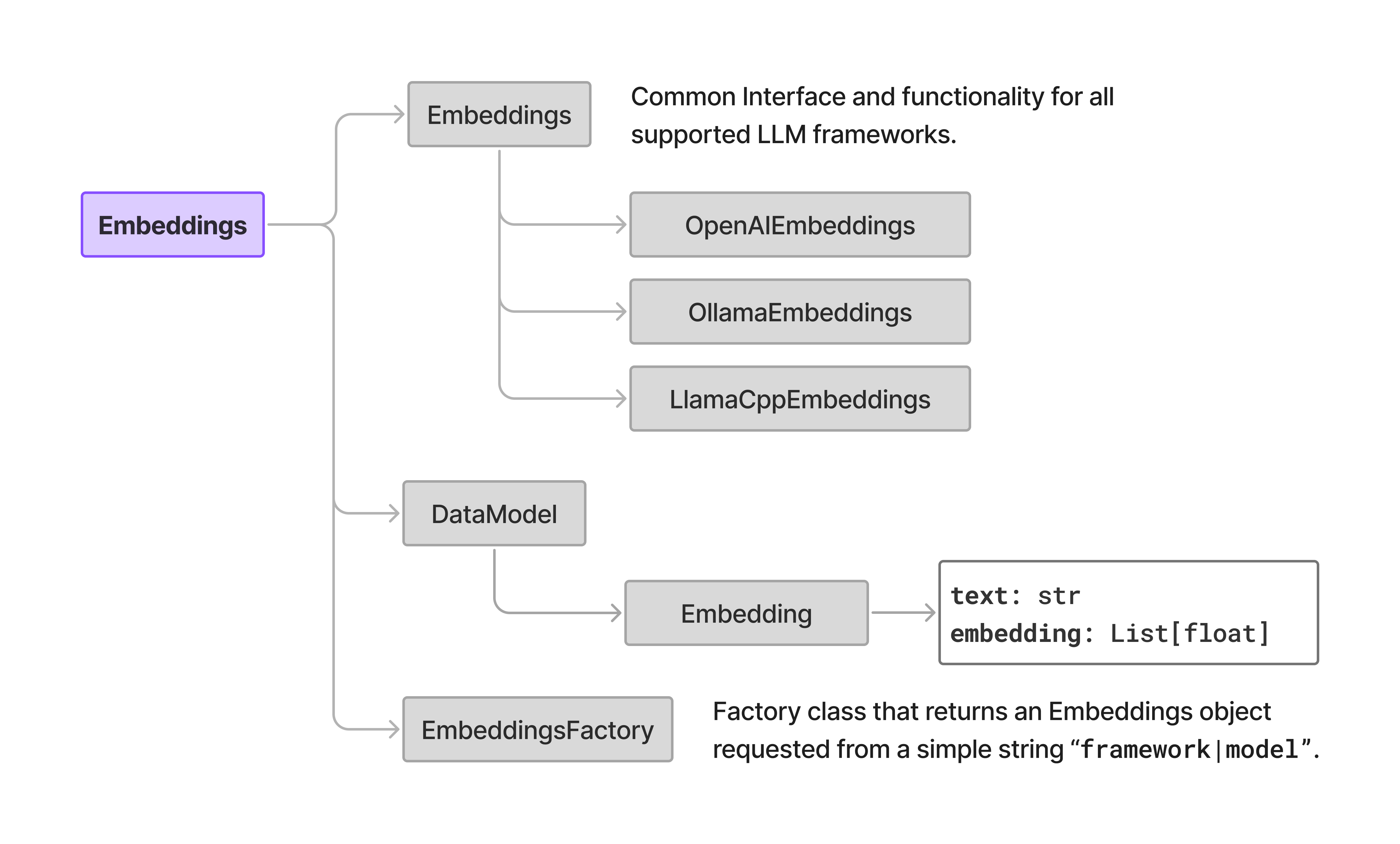
Embeddings class and framework specific classes i.e. OpenAIEmbeddings, OllamaEmbeddings, and LlamaCppEmbeddings. Data model component and factory class are also shown.Embedding class
Embedding models are used to convert text into numerical vectors that can be used for various natural language processing tasks. The Embedding class provides a common interface for different embedding model providers, allowing users to easily switch between different models without changing the code.
Main abstract function of this module is run which is defined in embeddings.py as:
def run(self, text: str) -> Embedding
This is the main function that any framework specific implementation needs to include. The method takes string input and runs the embedding model of the input. The result is an Embedding object that includes the original text and a list of floating point values being the embedding vector.
Framework specific embeddings classes
Each framework specific class will implement the initialization function and the run function that is provided as abstract in the base class. An example is the Ollama version of the run function:
def run(self, text: str) -> Embedding:
"""
Run the embeddings model with the given text.
Retry on failure.
:param text: The text to embed.
:return: The embedding, text pair object.
"""
@self._get_retry_decorator()
def _run(text: str) -> Embedding:
self._validate_text(text)
response = self._client.embeddings(
model=self._model_name,
prompt=text
)
embed = response["embedding"]
self._validate_embedding(embed)
return Embedding(
text=text,
embedding=embed
)
return _run(text)
This function is responsible for sending the input text to the Ollama model and receiving the embedding vector. It handles the formatting of the request and the parsing of the response. The text parameter is a string representing the input text, and the function returns an Embedding object containing the original text and the embedding vector.
Embeddings Factory
Embeddings Factory is a class that provides a factory method for creating instances of embedding models. It abstracts the process of instantiating different embedding classes based on the provided engine name and model parameters. The factory method is responsible for selecting the appropriate embedding class based on the engine name and returning an instance of that class.
def create(self, engine_name: str = None) -> Embeddings
This function creates an instance of an embedding model based on the provided engine name and model parameters. The engine name is a string that specifies the type of model framework and embedding model to be created in the format provider_name|model_name, where provider_name is the name of the embedding provider (e.g., openai, ollama, and llama_cpp) and model_name is the name of the specific model to be used.